
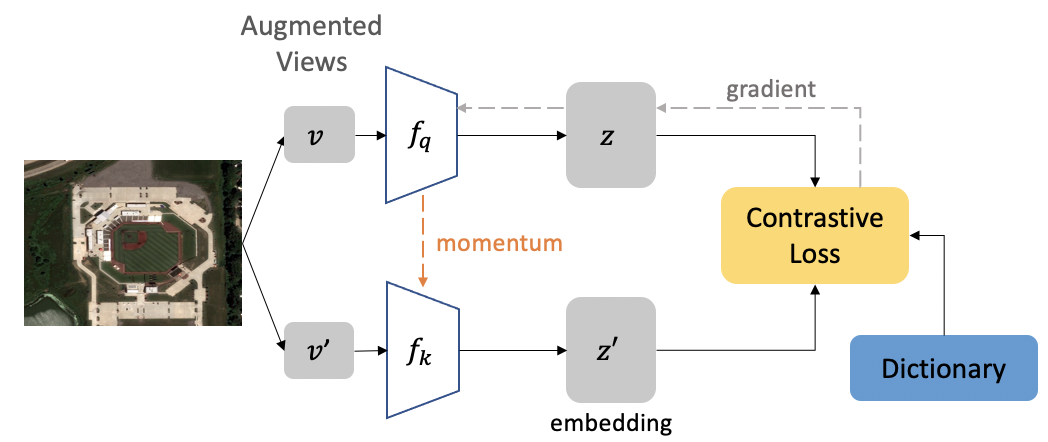
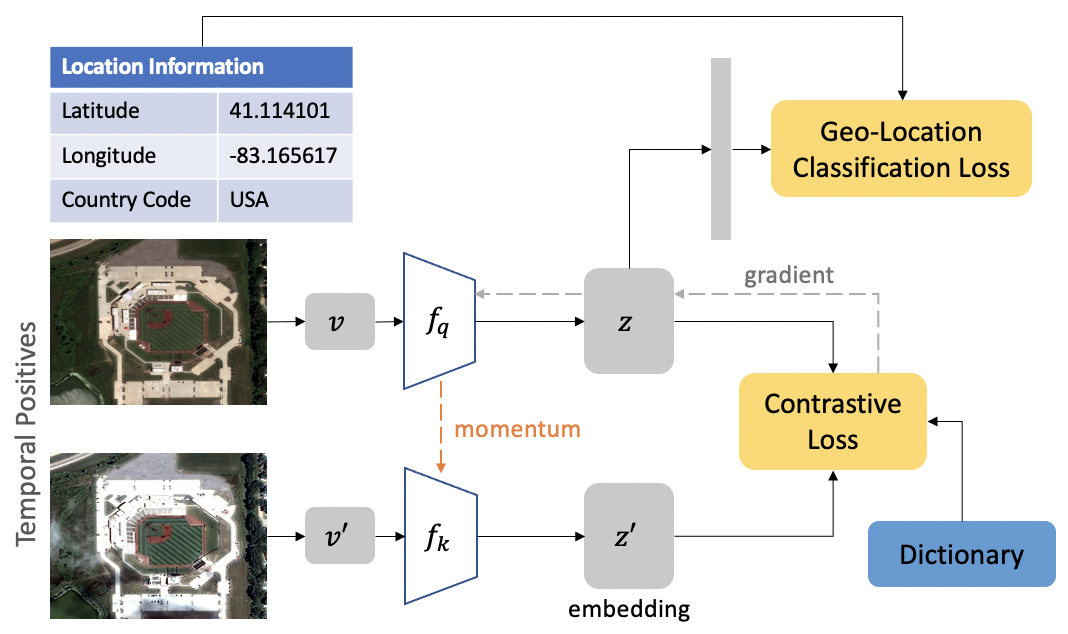
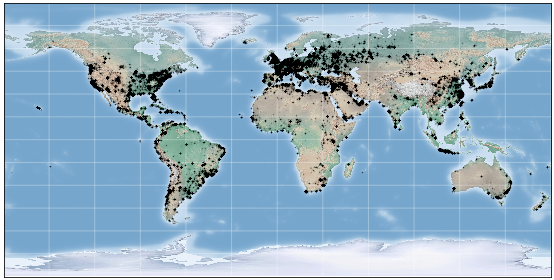
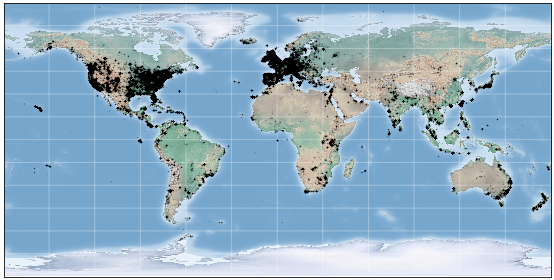
Contrastive learning methods have significantly narrowed the gap between supervised and unsupervised learning on computer vision tasks. In this paper, we explore their application to geo-located datasets, e.g. remote sensing, where unlabeled data is often abundant but labeled data is scarce. We first show that due to their different characteristics, a non-trivial gap persists between contrastive and supervised learning on standard benchmarks. To close the gap, we propose novel training methods that exploit the spatio-temporal structure of remote sensing data. We leverage spatially aligned images over time to construct temporal positive pairs in contrastive learning and geo-location to design pre-text tasks. Our experiments show that our proposed method closes the gap between contrastive and supervised learning on image classification, object detection and semantic segmentation for remote sensing. Moreover, we demonstrate that the proposed method can also beapplied to geo-tagged ImageNet images, improving down-stream performance on various tasks.

@article{ayush2021geography,
title={Geography-Aware Self-Supervised Learning},
author={Ayush, Kumar and Uzkent, Burak and Meng, Chenlin and Tanmay, Kumar and Burke, Marshall and Lobell, David and Ermon, Stefano},
journal={ICCV},
year={2021}
}

